
In short
- Retries help, but they are only one part of reliability.
- A robust setup needs retries, idempotency, DLQ, replay, and observability.
- If one piece is missing, incidents become slower and more expensive to resolve.
Most teams start with a retry loop and call it done. That feels practical at first. In production, it breaks quickly because webhook delivery is a distributed systems problem.
Retries are useful, but they are not the full system
Retries solve temporary failures. They do not protect you from duplicate side effects, hidden dead events, or retry storms.
A simple example: a downstream service slows down for 10 minutes. If every sender retries on the same schedule, traffic spikes and recovery gets harder.
Use a retry policy with clear boundaries
Start with clear rules so behavior stays predictable under pressure. Keep the policy small and explicit.
Retry on timeouts, 5xx responses, and selected 429 responses. Avoid automatic retries on most 4xx responses because they usually require a payload or config change.
Use exponential backoff and add full jitter. A practical schedule is 1s, 5s, 25s, 2m, 10m, and 30m.
Set both a max attempt count and a max retry window. For example, 6 attempts within 24 hours.
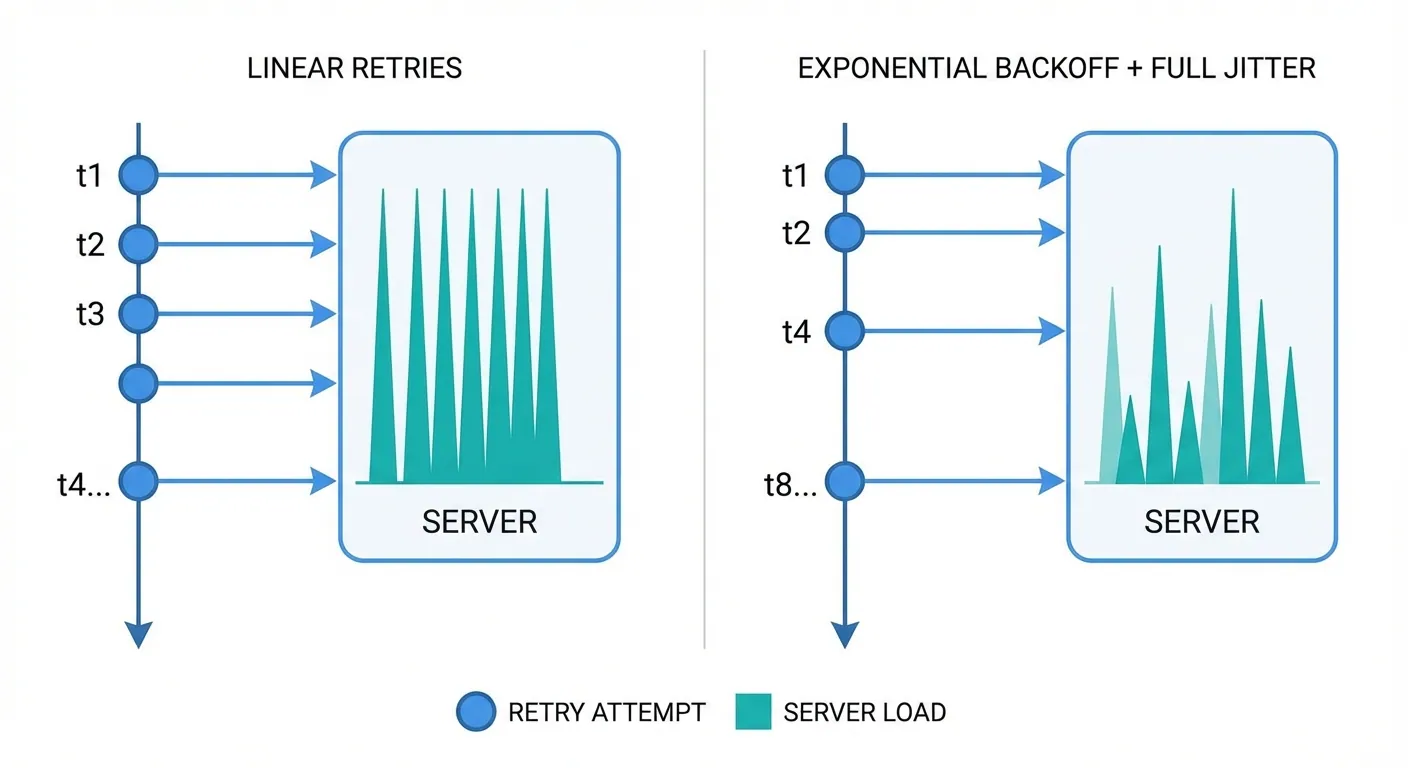
Idempotency protects your business logic
At-least-once delivery means duplicates are normal. Idempotency is what keeps duplicates harmless.
Use a stable event ID and enforce idempotency at the consumer boundary. Store dedupe records with a TTL that matches your risk window.
Example: for billing events, keep dedupe records longer and persist them reliably. This prevents duplicate charges during incident recovery.
DLQ and replay turn failures into recoverable work
A DLQ should be a recovery lane, not a dead end. It gives your team a safe place to handle exhausted deliveries.
Store enough context to replay safely: payload, headers, attempt history, and last error. Without this context, recovery becomes manual and error-prone.
Replay should support one event and filtered batches. One event helps surgical fixes, while batches help close larger incidents quickly.

Observability gives early warning
Good metrics tell you when reliability is drifting before customers report issues. This is where teams usually gain the most operational leverage.
Track success rate, retry depth, age of oldest undelivered event, DLQ backlog, and duplicate detection count. Alert on trend changes, not only hard failures.
Example: a rising retry-depth percentile often appears hours before a visible outage.
Common failure patterns to avoid
Some patterns look harmless in staging and become painful in production.
Avoid immediate retry loops, infinite retries, and blind retries for all 4xx responses. Avoid shipping without idempotency and replay tooling.
Monday-morning checklist
- Define retryable status codes.
- Implement exponential backoff.
- Add full jitter.
- Enforce max attempts and max retry age.
- Add idempotency key handling.
- Persist dedupe records with TTL.
- Route exhausted events to DLQ.
- Build replay tooling for single and batch recovery.
- Instrument success, retry, and DLQ metrics.
- Run one outage simulation.
{
"eventId": "evt_123",
"status": "queued",
"attempt": 1,
"maxAttempts": 6
}Where Hookwing fits
Hookwing is built for this exact operating reality. Deliveries fail, recover, and fail again under different conditions.
The goal is to make failure handling boring: clear retries, safe dedupe, visible queues, and fast replay.
Ready to ship with confidence
If you want a quick reliability upgrade this week, start with retry boundaries and idempotency. Then add DLQ and replay. That sequence gives the fastest reduction in incident pain.