
In short
- Idempotency is the fastest way to reduce duplicate side effects in webhook systems.
- You do not need a perfect architecture to start. You need clear keys, storage rules, and replay discipline.
- A small, consistent checklist will protect billing, inventory, and user-facing workflows.
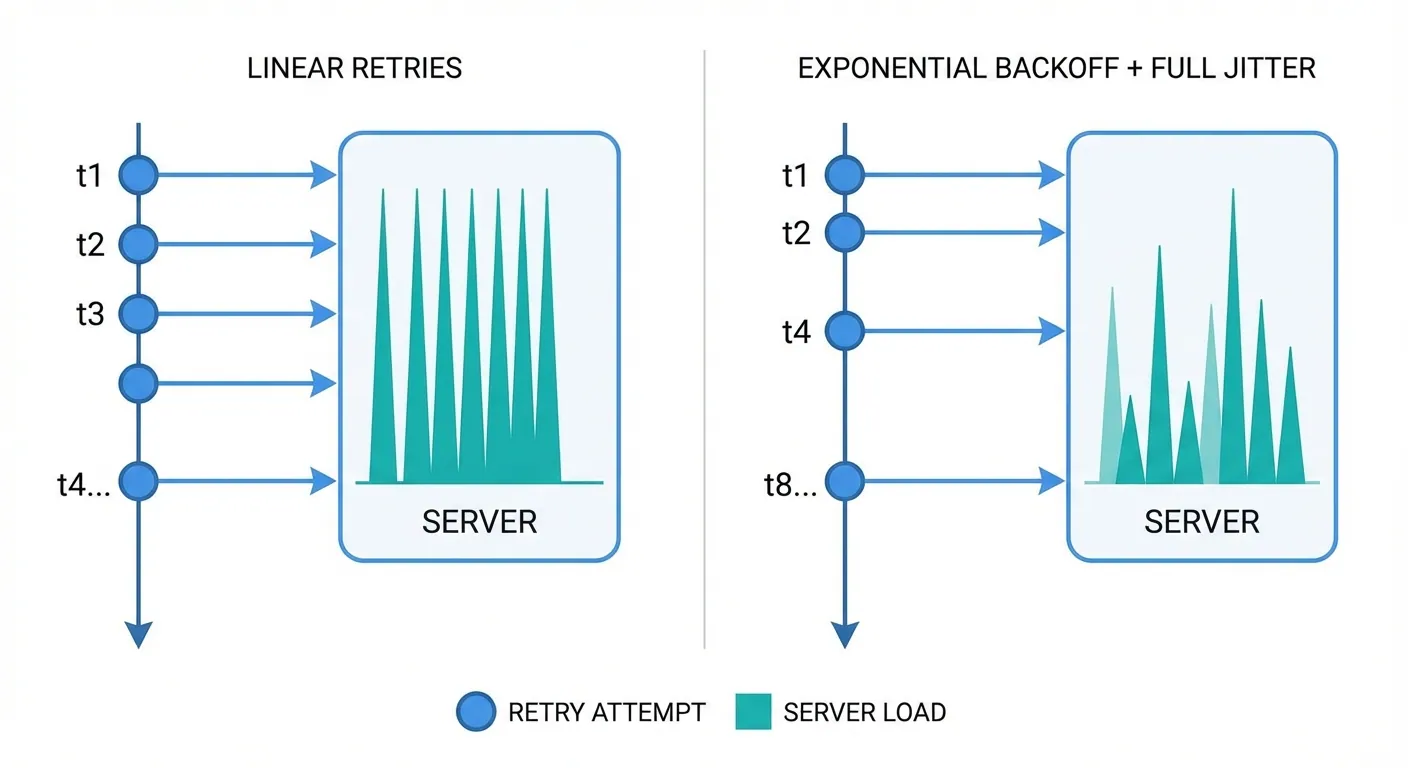
If your team is shipping quickly, duplicates will happen. That is normal in at-least-once delivery systems. The win is not to avoid every duplicate forever. The win is to make duplicates harmless.
Why idempotency matters earlier than most teams expect
A lot of teams postpone idempotency until scale. In practice, duplicate effects often appear during normal incidents: timeout retries, queue replays, provider retries, or manual resends.
A concrete example is billing. One duplicate event can become a duplicate charge, then a support ticket, then a trust issue. A small idempotency layer avoids that entire chain.
1. Define one stable idempotency key
Start with one key strategy and keep it consistent across services. This gives your team a shared contract.
Recommended order of preference:
- Provider event ID (if guaranteed stable)
- Delivery ID from your ingress layer
- Deterministic hash of business-critical fields
For HTTP semantics and status behavior, keep your handlers aligned with standard response expectations from RFC 9110.
2. Store dedupe decisions with a clear TTL
A dedupe key without retention policy creates confusion. Define how long a key should block duplicates based on business risk.
| Event type | Suggested TTL | Why | |---|---:|---| | Billing / payments | 30 days | Protect financial side effects and support investigations | | Subscription lifecycle | 7–14 days | Covers most retry and replay windows | | Non-critical notifications | 24–72h | Lower business risk, shorter storage cost |
If your team is unsure, start conservatively and reduce later with observed data.
3. Separate processing state from business success
Your dedupe store should track more than “seen yes/no.” Add state so operations stay clear during incidents.
Suggested states:
- received
- processing
- completed
- failed-retryable
- failed-terminal
This keeps replays safe and allows support teams to understand what happened without reading raw logs.
4. Handle race conditions explicitly
Two workers can process the same event nearly at the same time. If your key write is not atomic, duplicates can slip through.
Use one atomic guard pattern:
- unique key insert with conflict detection
- transactional upsert with lock
- compare-and-set with conditional write
The exact primitive depends on your datastore, but the principle is the same: one winner, everyone else exits safely.
5. Make replay a first-class workflow
Idempotency and replay belong together. Replays are useful only if they are predictable and auditable.
A safe replay flow should include:
- operator identity
- reason for replay
- event selection scope
- dry-run option for batch replay
- post-replay verification step
For delivery reliability context, pair this with your retry controls. See the related guide: /blog/webhook-retry-best-practices/.
6. Add visibility your team can act on
A checklist is only complete when people can see where the system is drifting.
Track at least:
- dedupe hit rate
- duplicate side-effect incidents
- replay success rate
- key-store latency percentiles
If one metric rises unexpectedly, your team should know exactly where to look first.
7. Keep implementation practical
You do not need a huge platform rewrite to get value. Start with one high-risk flow and expand.
A practical rollout path:
- Protect one critical endpoint (billing or entitlement).
- Add key storage + conflict handling.
- Add replay metadata.
- Add dashboards/alerts.
- Expand to next endpoint.
This approach keeps momentum high and makes reliability gains visible quickly.
Ready to ship with confidence
If you want the safest first week, implement idempotency keying + TTL + atomic conflict handling first. Then add replay ergonomics and visibility. That sequence gives strong protection with minimal friction.
For onboarding patterns and deployment workflow, you can also check /docs/getting-started/ and /blog/cloudflare-preview-ops/.